过拟合及解决办法
过拟合是机器学习任务中非常普遍的现象,模型不仅拟合了样本的普遍规律,还进一步拟合了噪声。
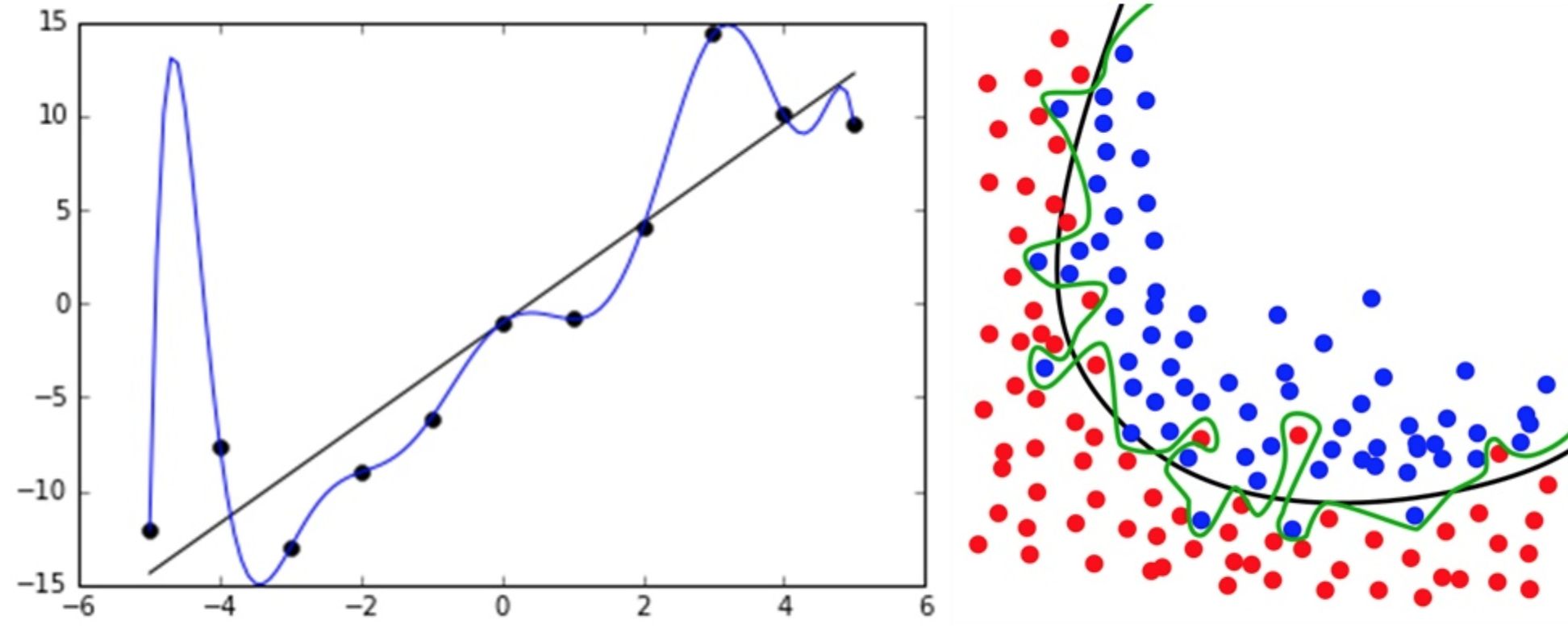
理解过拟合
The word overfitting refers to a model that models the training data too well. Instead of learning the genral distribution of the data, the model learns the expected output for every data point.
简单讲,模型不仅把所有潜在样本的普遍规律学习到了,还把训练样本本身一些特点当做所有潜在样本都会有的一般性质学习到了,导致泛化性能降低。过拟合的极限可以把所有样本都完全记住。
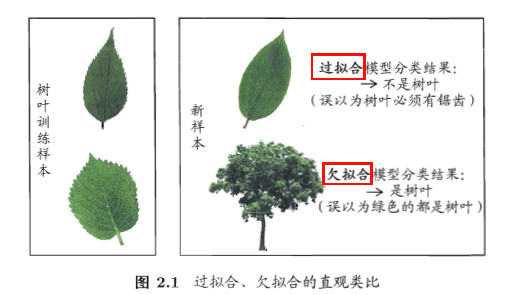
如上图中比较直观的例子,模型误以为锯齿是树叶必备的特征。
过拟合原因
林轩田老师在机器学习技法中讲到,过拟合主要有三个原因
- excessive $d_{vc}$
- noise
- limited data size $N$
模型拟合能力过强、样本存在噪音以及样本量不足都可能导致过拟合。
总之
Overfitting is everywhere。
下图是探索样本噪音和样本量对过拟合影响的数值模拟实验。
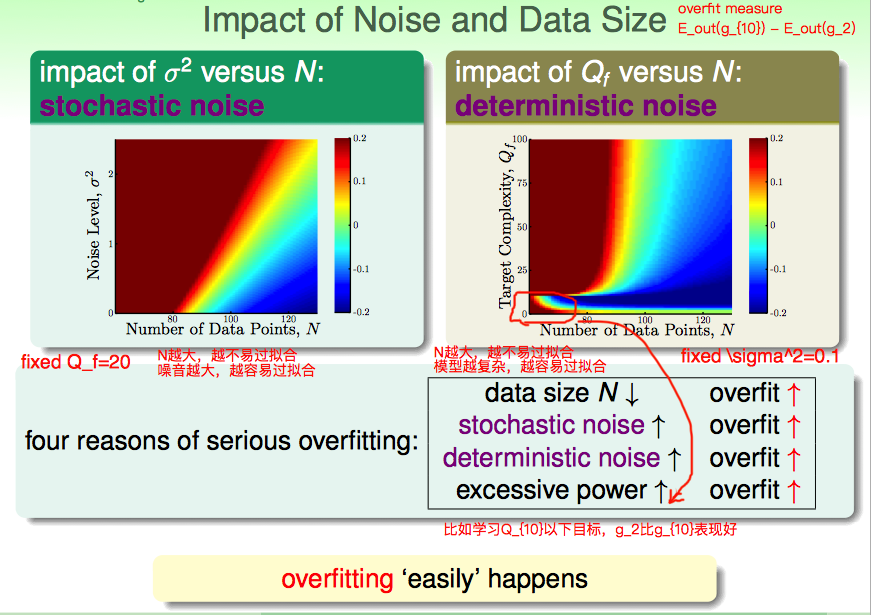
不难看出一些规律
- 样本量越大越不易过拟合
- 样本噪音越大越容易过拟合「stochastic noise」
- 目标函数越复杂越容易过拟合「deterministic noise」
解决过拟合
知道过拟合原因后,可以更好理解经典的对抗过拟合的手段。林轩田老师把过拟合类比成开车翻车,同时将防止翻车的手段对应到对抗过拟合的手段。

一份不完全清单
- 从简单模型开始,尤其当样本量较少时
- 增加数据量,比如CV中常用的Data Augmentation
- 正则化
- Bagging/Boosting
- Dropout
- Early Stopping
- …
