09 Linear Regression
介绍了线性回归算法,问题的解以及泛化误差分析,见详细课件。
关注几个核心问题:
- 问题的Formulation
- 最小二乘求解步骤
- 算法Intuition
- 误差公式推导以及泛化问题
Formulation
线性回归问题Formulation是,假设输入空间为
linear regression hypothesis为
即
求解目标是使$E_{in}(w)$最小,其表达式如下
方便推导,写成矩阵形式

求出使$E_{in}(w)$最小的$w$,就是我们最终需要的解。
求解步骤
$E_{in}(w)$ continuous, differentiable and convex, close form solution exists.
问题是连续可导且凸,存在解析解,对$E_{in}(w)$求导,使导数为零,即可得到。将其展开,不难得到
因为向量內积满足交换律,不难得到$y^TXw = w^TX^Ty$。
对列向量$w$求导,求导过程中用到几个性质,将$w$展开很容易证明
- $\nabla_w(w^Tb) = b$
- $(w^TAw) = \sum \sum w_iw_jA_{ij}$
- $\nabla_w(w^TAw) = (A + A^T)w$
不难得到
得到ordinary least squares(OLS)解。
其中$X^+=(X^TX)^{-1}X^T$称为pseudo-inverse of X。算法汇总到一张Slide如下

算法Intuition
首先引入Hat Matrix的概念
其中$H=X(X^TX)^{-1}X^T$叫做Hat Matrix。
The estimate $\hat y$ is a linear transformation of the actual $y$ through matrix multiplication with $H$.
根据Hat Matrix的表达式,很容易证明有如下性质
- $H^T=H$
- $H^K=H$
- $(I-H)^K=I-H$
- $trace(H)=d+1$
- $trace(I-H)=N-(d+1)$
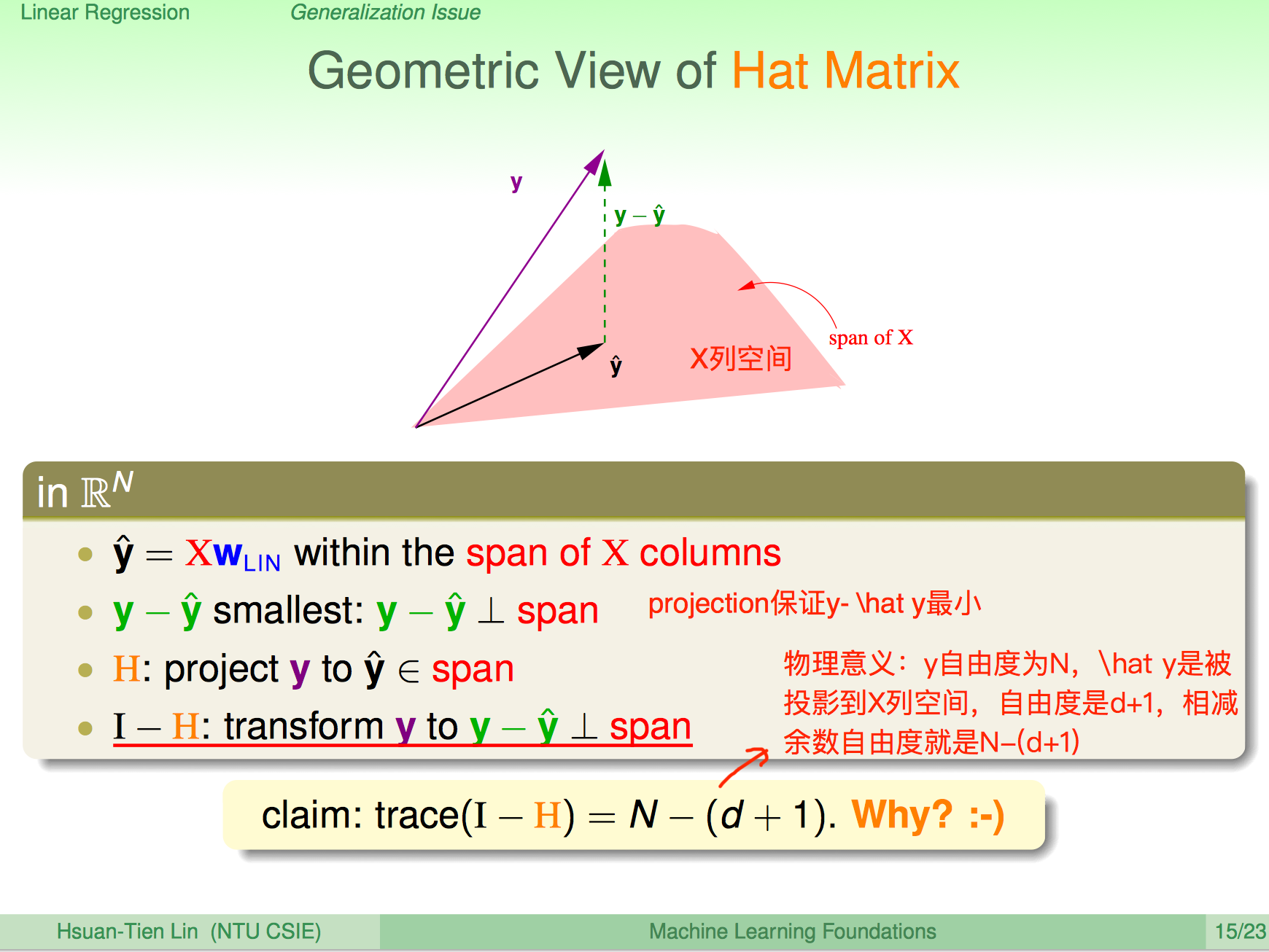
Hat Matrix直观几何意义就是将$y$投射到$X$的列空间。
误差推导
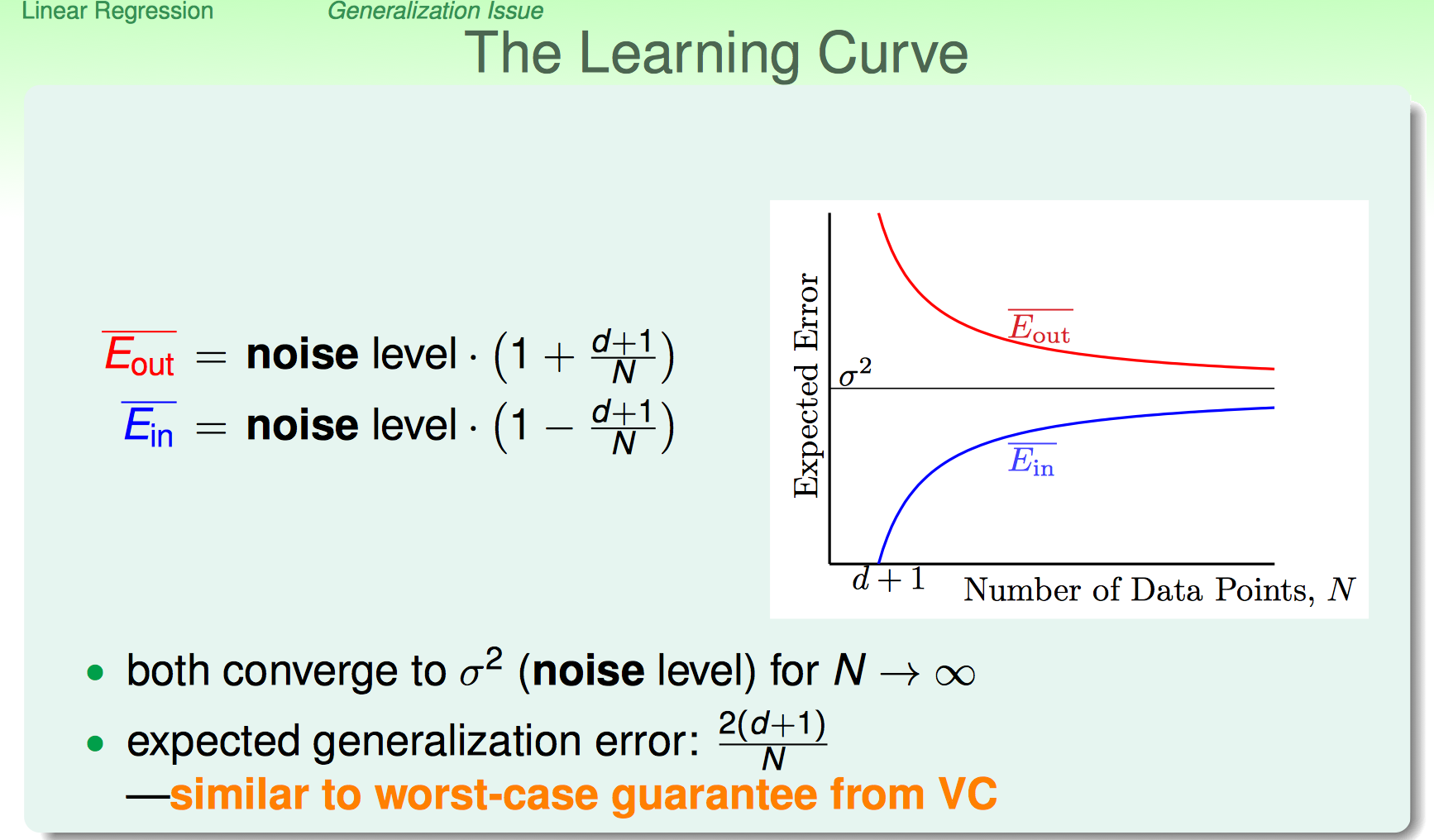
课程给出$\bar E_{in}(w)$比较直观的推导。

数学上简单证明
基本假设是线性函数加上噪音
代入下面式子
然后再将$y$表达式反代回来
得到
所以
对其求期望
其中
以及
$\epsilon_i$和$\epsilon_j$相互独立,且其期望都为0。
最终的到Learning Curve如下